Software Architecture Documentation
- SK
- Hari Krishnan (Unlicensed)
- Patricia Wanninger
- Rajesh Babu K
Introduction
Purpose
Architecture represents the significant design decisions that shape a system, where significance is measured by cost of change. This document details the high-level architecture for the ReCAP middleware system called "Shared Collection Service Bus(SCSB)". The description of the architecture uses a number of different views to capture and convey the significant architectural decisions which have been made on the system.
The SCSB solution will be designed and developed in line with the High Level Architecture. The High Level Architecture identifies seventeen (17) architecturally significant use cases.
Document Overview
The architecture of the application is represented using the recommendations of the Rational Unified Process guidelines. This document also highlights the development environment, quality requirements and prototyping details.
The UML (Unified Modeling Language) specification of the new ReCAP middleware system Shared Collection Service Bus(SCSB) has been divided into multiple views:
- Business Process View – Swim lane diagrams
- Use Case View –illustrates and validates the architecture by presenting selected architecturally significant use cases which describe functional requirements.
- Logical View – illustrates the object model of the design. It presents an analysis model, which captures the analysis of the use cases and a design model. This view also describes the logical structure of the system and presents key structural and behavioral elements.
- Process View – illustrates the assignment of components to the operating system processes and threads.
- Implementation View - describes the physical organization of the software and its components in the production environment.
- Deployment View –illustrates the mapping of the software to the hardware and its distribution aspects.
Audience
The primary audience for this document is the Development team and QA team. The development team will use it to help aid the detailed design during the development phase and ultimately to develop the system. The QA team will use it to ensure testability and also to ensure that proper test cases are written.
Each view as presented in the "Document Overview" section primarily caters to different audience.
- Business Process Diagram - All
- Use Case view – All
- Logical view – Development team
- Process view – Software Integrators (part of the development team), QA team to understand performance and scalability bottlenecks for testing purposes
- Implementation view – Development and Deployment teams(part of development team)
- Deployment view – Deployment and Production Support Teams
Definition for Architecture
This document uses the architecture definitions presented by Software Architecture in Practice (at ReCAP; https://clio.columbia.edu/catalog/2113877):
"The software architecture of a program or computing system is the structure or structures of the system, which comprise software components, the externally visible properties of those components, and the relationships among them."
UML Modeling Language User Guide defines "Software Architecture" as:
"An architecture is the set of significant decisions about the organization of a software system, the selection of the structural elements and their interfaces by which the system is composed, together with their behavior as specified in the collaborations among those elements, the composition of these structural and behavioral elements into progressively larger subsystems, and the architectural style that guides this organization---these elements and their interfaces, their collaborations, and their composition. "
Scope of the Work
This document provides the candidate architecture for the ReCAP SCSB, which includes details for each layer (Presentation, Enterprise Services, Data Services, and Data) and the interfaces to ILS, Discovery and GFA LAS systems.
HTC's scope of work broadly covers the following:
- Design, development, testing, implementation and maintenance of SCSB with the following functionalities:
- Search SCSB Collection
- Request Item
- Validate Request
- Place Hold on Item
- Recall Item
- Ongoing Accession Item
- Deaccession Item
- Re-file Item
- Check Item Availability
- Get Shared Collection Items
- Submit Collection Information
- Receive Collection Updates
- Search for Requests
- Initial Accession Records
- Process EDD Request
- SCSB Matching Algorithm
- Develop an API to enable SCSB to communicate in real time with the partner libraries and inventory management system
- Provide Implementation and Support services for the hosting environment (in a cloud-based hosting environment)
Project Goals
This section provides the business needs, project goals and architectural issues with the current system and explains how the new ReCAP SCSB architecture aims to address these issues. This section provides a business perspective to the architecture and establishes architectural goals, assumptions and constraints.
Project Scope and Objectives
"The scope of the project is to expand the vision of the ReCAP facility from a shared storage facility to a shared collection with enhanced access to the patrons of each of the participating libraries by implementing an integrated SCSB utilizing established industry architectures. The functional requirements for SCSB will encompass all of the existing functionality, plus changes and enhancements to improve user experience and collection management".
The ReCAP project has the following main objectives:
- Improve visibility of ReCAP shared collection items from any participating institution in Partners' Discovery Systems.
- Display of real-time status of items in ReCAP, including availability for request, restrictions and available pick-up locations
- Improve services that can be embedded into the online catalog or discovery services of the participating institutions to capture and validate requests made by patrons or by library staff for ReCAP materials
- Provide real-time tracking for ReCAP materials requested by patrons from the time that they leave the ReCAP until they are returned for refiling
- Provide tools to support the management of the ReCAP collection, such as collaborative collection development, automated processing of duplicates, or designation of preservation retention.
Architectural Challenges with Current System
- Shared Collection Visibility – Items placed in shared collection by other partners is not available in the OPAC systems, limiting access of such items to patrons
- Real-time Availability – ReCAP item status is unavailable in OPAC or ILS
- Real-time Request Processing – Request processing is batch only with minimal validations and error reporting
- Real-time Status Reporting – Overall status of items between ReCAP facility and delivery locations are partially captured and distributed across disparate systems
- Collection Management – No centralized collection management is in place
How the New Architecture Addresses the Challenges
- Shared Collection Visibility – ReCAP middleware consolidates and normalizes ReCAP item and bib records from all three partners and pushes update feeds to all partners. ReCAP search service provides ability to perform search on shared collection from Middleware Search UI. ReCAP will provide the records of the other Partners on incremental or full basis and Partners will provide the indexing.
- Real-time Availability – ReCAP middleware database maintains real-time status of all ReCAP items. Item availability is provided through ReCAP middleware API.
- Real-time Request Processing – ReCAP middleware maintains validation rules and item status. Request submitted through Discovery forms are validated real-time, processed in the Partner ILS and recorded in ReCAP middleware database. Users receive confirmation or validation error messages in real-time enabling them to resubmit a valid request.
- Real-time Status Reporting – ReCAP middleware consolidates a complete view of item status across GFA and ILS systems into middleware database. Consolidated status can be leveraged for tracking and analytics.
- Collection Management – ReCAP middleware implements centralized automated collection classification algorithm. Middleware provides user interfaces for manual workflow steps such as withdrawal of preservation copies.
Architectural Overview
High Level Architecture
SCSB will enable efficient, real-time transactions between the integrated library systems (ILS) of NYPL, Columbia University and Princeton University, their web-accessible discovery environments, and the ReCAP inventory management system (IMS).
SCSB is designed to provide
- Real-time availability of all shared collection items in OPAC systems
- Validate and process the requests in real-time
- Provide real-time item status
- Integration with Partner ILS to support requesting and circulation. Support of collection management rules
- Support existing workflows and user experience
- Eliminate cross loading bibliographic and item records in ILS (Voyager, Sierra)
The following diagram represents the environment (of the collaborating systems) where the solution fits in. The block named "Middleware" represents the solution being developed and implemented. 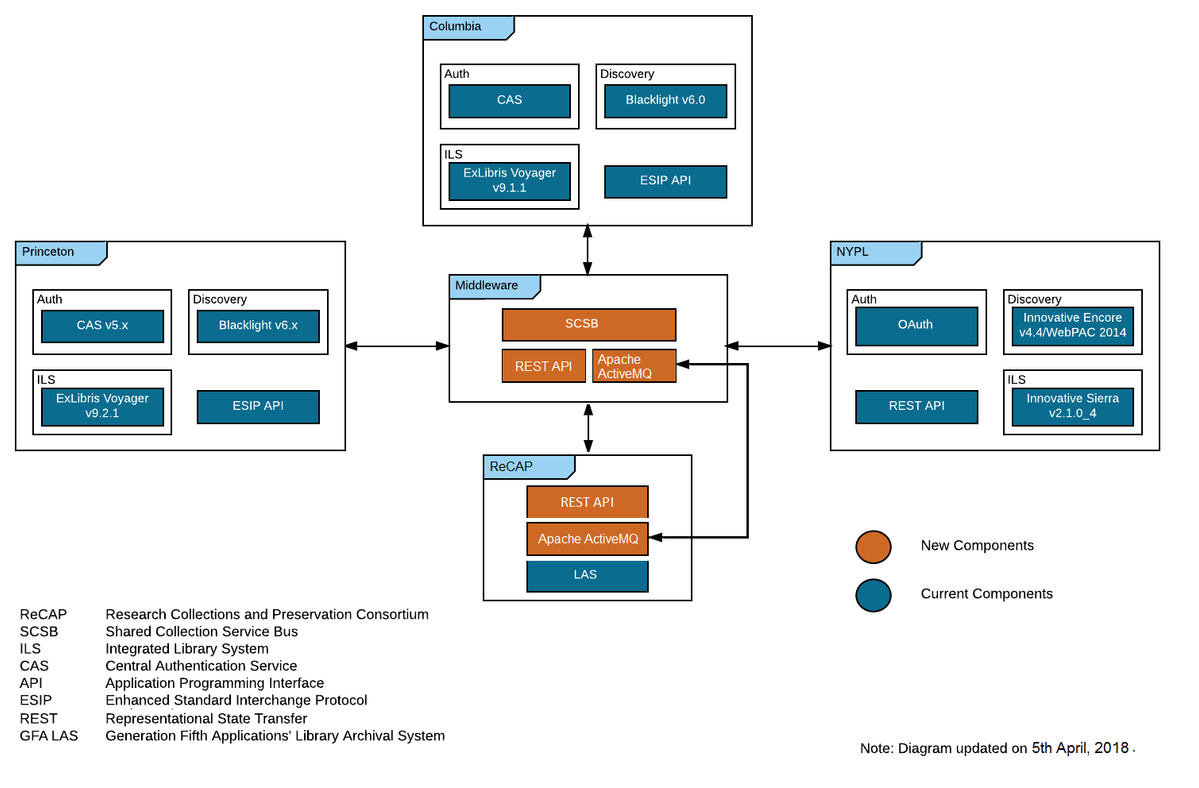
Layered Architecture
The architecture includes four distinct layers:
- Presentation Layer
- Services Layer
- Data Services Layer
- Data Layer
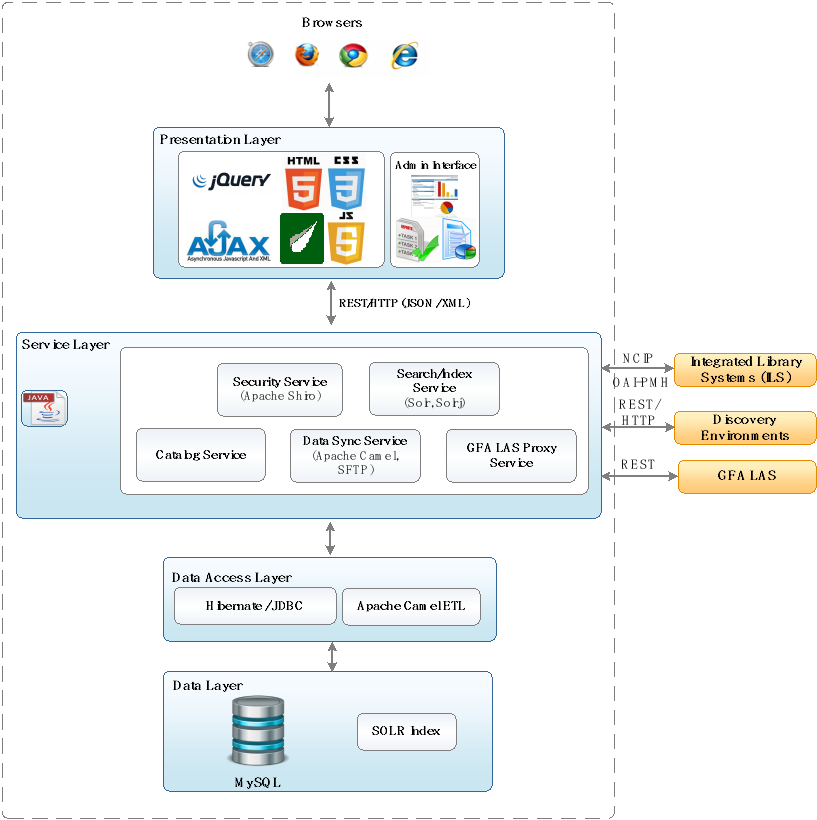
Presentation Layer
The presentation layer deals with user interface aspects of the system.
Services Layer
The services layer encapsulates specific business rules, which are made available to the presentation layer. The presentation layer requests enterprise services, which are then fulfilled by this layer. The architecture envisages providing a seamless enterprise service layer communicating with internal data stores and 3rd party services. The data access layer supports the enterprise service layer by serving the data required.
Data Services Layer
The data services layer provides fundamental services to fulfill the business needs (fulfilled through enterprise services) such as Search, Request Item, etc. The data services layer serves data required by enterprise services. Data services support both relational database and Solr.
Services implementing data access to relational database will leverage Java Persistence Architecture (JPA), providing separation of object persistence and data access logic from a particular persistence mechanism (relational database) in data layer. This approach provides the flexibility to change the applications persistence mechanism without the need to re-engineer application logic that interacts with the data layer. Persistence classes are developed following the object-oriented idiom including association, inheritance, polymorphism, composition, and collections. This framework provides the flexibility to express queries in its own portable SQL extension, as well as in native SQL, or with object-oriented criteria.
Services implementing data access to Solr / Lucene search will wrap the Solr RESTFul API's to provide features such as search, filter, sort and navigation.
Data Layer
The data layer serves as the data store for all persistent information in the system including the relational database and search engine indexes.
RDBMS data layer will comprise of MySQL cluster. RDBMS data layer will be accessed only from the data access layer via Data Access Objects (DAOs). RDBMS cluster architecture allows a single physical database to be accessed by concurrent instances running across several different CPUs. The proposed data layer will be composed of a group of independent servers or nodes that operate as a single system. These nodes have a single view of the distributed cache memory for the entire database system providing applications access to more horsepower when needed while allowing computing resources to be used for other applications when database resources are not as heavily required. In the event of a sudden increase in traffic, proposed system can distribute the load over many nodes, a feature referred to as load balancing. In addition to this, proposed system can protect against failures caused by unexpected hardware, operating system or server crashes, as well as processing loss caused by planned maintenance. When a node failure occurs, connection attempts can fail over to other nodes in the cluster, which assumes the work of the failed node. When connection failover occurs and a service connection is redirected to another node, users can continue to access the service, unaware that it is now provided from a different node.
A single Solr instance can support more than one index using Solr cores (single index per core). A single large index can be a performance overhead. SolrCloud distributes a single index on different machines, commonly referred as shards. All shards of the same index making one large index are referred as collection. While collection supports index scaling, it does not provide redundancy. Replication of shards provides redundancy and fault tolerance.
Zookeeper maintains the SolrCloud, by distributing the index across shards and federating the search through the collection. SolrCloud uses leaders and an overseer. In the event of leader or the cluster overseer failure, automatic fail over will choose new leaders or a new overseer transparently to the user and they will seamlessly takeover their respective jobs. Any Solr instance can be promoted to one of these roles.
Logical Architecture
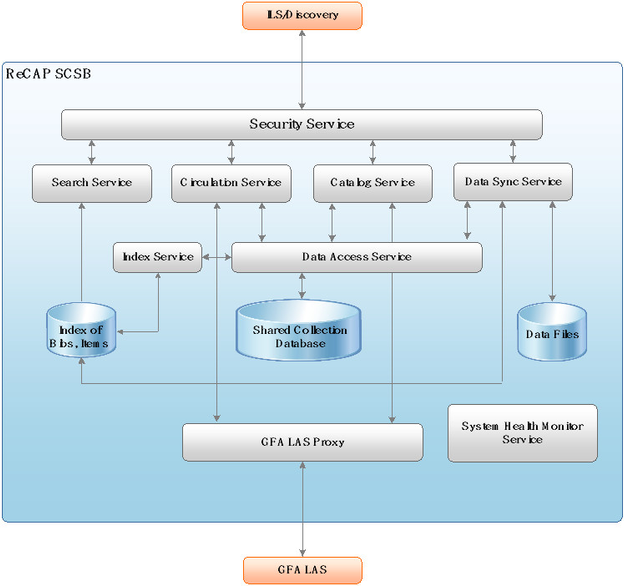
Architectural Views
Business Process Overview
Current State: Currently, partners submit items to the ReCAP facility and they are accessioned in a batch process. Information about the accession is returned to the partners, also in a batch. Requests for retrieval are made by partners from web forms set up by each partner, which are written to a batch. Requests are submitted a number of times a day and the batches are processed by ReCAP staff at set times. Some requests fail due to a variety of circumstances, but many because the item requested in in the ReCAP facility but on a re-file order. When items are returned to the facility, they are processed onto a re-file order, which can remain open for some time before the item is actually returned to its tray. Currently, there is no database with bibliographic information that conforms to what is in ReCAP, and each partner's collection is separate and maintained by only that partner's rules.
Future State: Information Real-time status information of the items will be known to partners. Requestors will call a web service to transmit information to ReCAP in real-time. The partner's ILS systems will manage the requests for patrons in real time. The system will allow for the creation of a bibliographic database that reflects what is contained in the ReCAP facility and allow for the creation of a Shared Collection with policies that enable sharing that extends the usage of these materials to the patron of a partner's institution on the same basis as if they were owned by that institution.
Functional Requirements View
The Architecturally significant Use Cases identified during the High Level Architecture definition are listed in the model below. 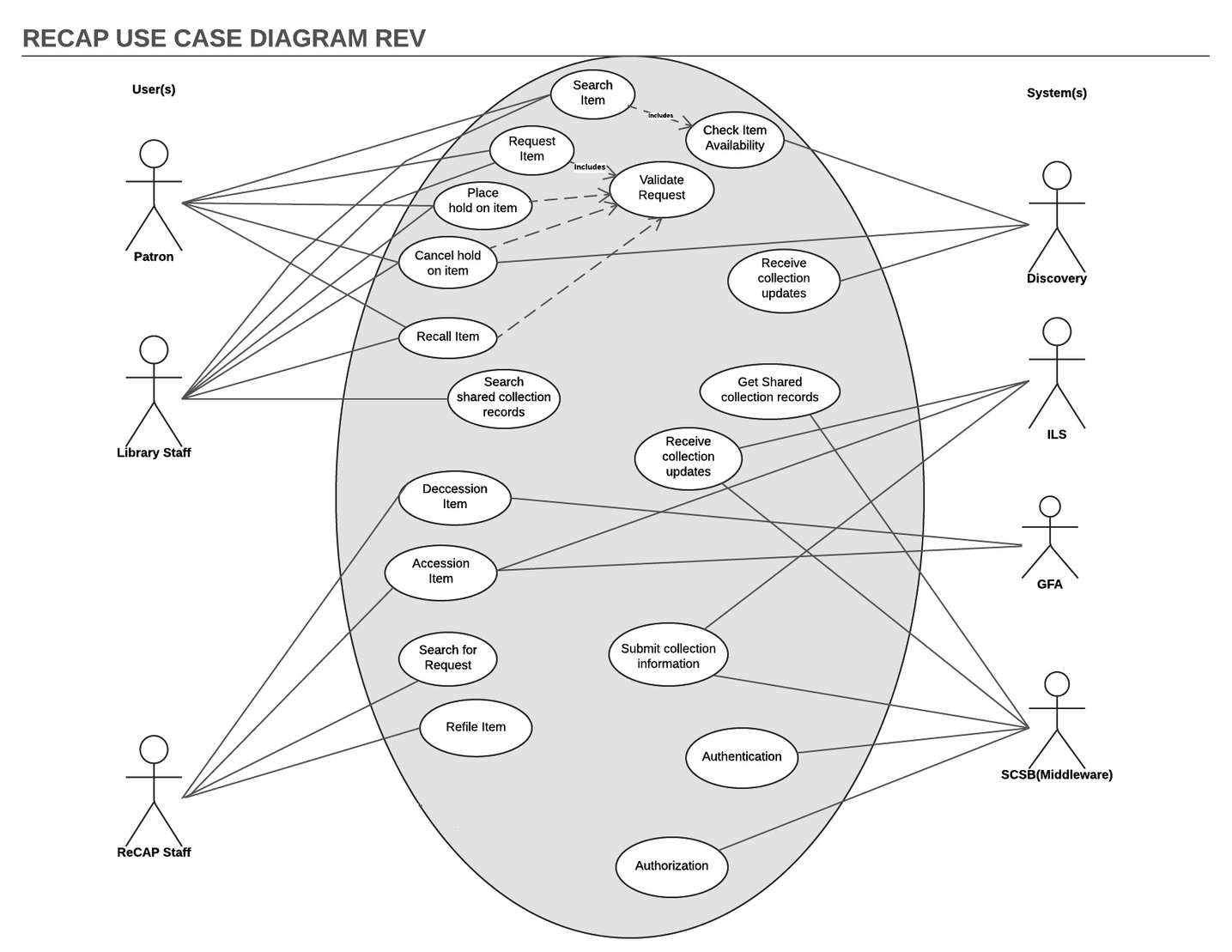
The following table lists the actors (user or system) interacting with the system.
No. | Actor | Description |
1 | Patron | A library patron is someone who uses a library, a university student or a city resident. Typically, this person gets a library card, browses the available books, CDs, DVDs, etc. |
2 | Library Staff | A library employee, who is responsible for a collection of specialized or technical information about items and management of items in a library. |
3 | ReCAP Staff | A Person responsible for day to day activities at GFA facility including accessioning, deaccessioning, filing, re-filing, etc. |
4 | Discovery | A Discovery Service is a software tool that allows for searching across a variety of platforms, such as a library catalog and a database of journal articles on a specific topic provided by a vendor. Example: Bibliocommons, Backlight; Ebsco Discovery Service. |
5 | ILS | An integrated Library System (ILS) is an enterprise resource planning system for a library, used to track items owned, orders made, bills paid, and patrons who have borrowed. |
6 | GFA LAS | Generation Fifth Applications Inc's Library Archival System catalogs and controls archival storage information in ReCAP facility |
7 | BorrowDirect | BorrowDirect is an unmediated library resource sharing partnership encompassing twelve Ivies plus academic institutions supplying over 250,000 books, music scores and other returnable library items. |
The following lists the architecturally significant use cases that describe the functional requirements of the system:
No. | Use Case Name | Architecture Complexity |
1 | Search SCSB Collection | Complex |
2 | Request Item | Complex |
3 | Validate Request | Simple |
4 | Place Hold on Item | Complex |
5 | Recall Item | Complex |
6 | Ongoing Accession Item | Medium |
7 | Deaccession Item | Medium |
8 | Re-file Item | Complex |
9 | Check Item Availability | Complex |
10 | Get Shared Collection Items | Medium |
11 | Submit Collection Information | Medium |
12 | Receive Collection Updates | Medium |
13 | Search for Requests | Medium |
14 | Initial Accession Records | Medium |
15 | Process EDD Request | Medium |
16 | SCSB Matching Algorithm | Medium |
A brief description of the architecturally significant use cases has been listed below. Each of the use case descriptions includes key business rules and includes reasons for architectural significance.
Search Shared Collection Items
In this use-case the patron will search via Partner's discovery for institution items as well as shared collection items placed by other ReCAP partners, based on the Partners' own parameters. A Search UI for use by staff is also provided.
https://www.lucidchart.com/documents/view/73d3fc0f-f030-4e01-99f7-2e680fbe4b2f/0
Architectural Significance
- Core Functionality
- Complexities –Includes collecting bibliographic and item data from all three partners, normalizing and indexing the data and providing offline feed or API for Discovery systems.
Request Item
In this use-case a patron will request the retrieval of an available ReCAP item by submitting the request through a web form. The form will submit the request to middleware API, which will invoke other use-cases to process the request. A Request UI is also provided.
https://www.lucidchart.com/documents/view/cd607093-d2d5-454e-962b-81932a90f809/0
Architectural Significance
- Core Functionality
- Complexities – ReCAP middleware will interact with GFA LAS, ILS and Discovery to process the request. It will create a temporary item record in one of the three applicable ILS depending upon the patron.
Validate Request
Request item use-case will invoke this use-case to validate the request for requested item, delivery location, delivery type, etc. Upon successful validation control will be returned to the main use-case with a confirmation message and upon unsuccessful validation an error message will be returned.
Architectural Significance
- Core Functionality
- Complexities – ReCAP middleware will validate against various policies and parameters including:
Customer code
Use Restrictions
Pick up location
Hold expiration date
EDD details
Email address
Place Hold on Item
In this use-case a patron will place hold against an item whose status is currently unavailable.
https://www.lucidchart.com/documents/view/cd607093-d2d5-454e-962b-81932a90f809/0
Architectural Significance
- Core Functionality
- Complexities – ReCAP middleware will place holds in the respective ILS as well as maintain a single hold queue for all the partner institutions in a first-in, first-out basis.
Recall Item
In this use-case a patron/library staff will recall an item whose status is currently unavailable.
https://www.lucidchart.com/documents/view/cd607093-d2d5-454e-962b-81932a90f809/0
Architectural Significance
- Core Functionality
- Complexities – ReCAP middleware will interact with owning or borrowing institution ILS to send the Recall request and maintain the queue in middleware database.
Accession Item
In this use-case ReCap staff will accession an item into the facility and the ReCAP middleware will interface with each Partner's database and return the bibliographic, holdings, and item data that matches the accessioned barcode. The middleware will check the accessioned item status and then apply accessioning algorithm.
The algorithm identifies titles where more than one copy is housed at ReCAP. Three Collection Group Designations have been defined by the Partners: Shared, which is defined as a single copy that is committed for sharing to all partners, and to permanent retention; Open, which is open to sharing by all partners but either a duplicate or not committed for permanent retention; Private, which are items that will be viewable and requestable only by the owning institution The accessioning algorithm identifies items that are duplicates. Only items in customers codes that are designated as Shared are subject to matching. Item information with assigned collection codes will be returned back to the owning libraries through SFTP drop. ReCAP staff also participates in the accessioning of an item
https://www.lucidchart.com/documents/view/98626f09-9e53-45ca-bb79-111528becc98/0
Architectural Significance
- Core Functionality
- Complexities – Accessioning algorithm will be run every time an item is accessioned in ReCAP. Accessioning algorithm includes a tie-breaker to cover most of the scenarios. Match and normalize disparate bib and item data across three partner ILS and GFA LAS. The item barcodes and applied circulation codes data will be returned to owning partner ILS.
Deaccession Item
In this use case Library Staff will initiate a request to deaccession an item through staff interfaces. Based on the collection code a manual approval workflow will be triggered to deaccession the item. ReCAP staff also participates in the deaccessioning of an item.
https://www.lucidchart.com/documents/view/73d3fc0f-f030-4e01-99f7-2e680fbe4b2f/0
Architectural Significance
- Core Functionality
- Complexities – ReCAP middleware will run accessioning algorithm to reassign circulation codes for other items after deaccessioning an item. A review/approval workflow will be implemented to manage preservation collections.
Re-file Item
In this use-case middleware will poll GFA LAS for re-filed items periodically, if an item is re-filed and has no hold or recall queue against it, its status will be changed to available. If a hold/recall queue exists the item will be processed for the first patron in the queue.
https://www.lucidchart.com/documents/view/56036afe-8d82-40d8-a471-b949358ab1f4/0
Architectural Significance
- Core Functionality
- Complexities – ReCAP middleware will actively poll GFA LAS to get the current status of the item. Once the item is checked-in (GFA), ReCAP middleware will process the item for next patron in queue and update corresponding ILS system.
Check Item Availability
In this use-case OPAC will request for a real-time availability status of an item from ReCAP middleware. Middleware API will return the status from the index which is maintained in sync with the transaction database.
https://www.lucidchart.com/documents/view/c3a989fe-12c8-4994-a585-0372819e103c/0
Architectural Significance
- Core Functionality
- Complexities – Real-time Item status will be provided through search API which is maintained in sync with the ReCAP database. Update search engine index without performance degradation.
Get Shared Collection Records
In this use-case Discovery systems will retrieve the other partners' shared collection records from SFTP server. The bib and item record will be normalized during inbound process and will be de-normalized during the outbound process to fit each partner's needs. The outbound records will be limited to other institutions 'shared collection items.
https://www.lucidchart.com/documents/view/3fda6346-1b89-438d-9192-029371dc0b58/0
Architectural Significance
- Core Functionality
- Complexities –De-normalizing feeds for all applicable Discovery systems.
Submit Collection Information
In this use-case partner ILS system will provide collection information, new accessions and updates to bibliographic data through SFTP upload. Middleware will process data from all partners, normalize the data and ingest into middleware database. The normalized data will be updated to ReCAP index.
https://www.lucidchart.com/documents/view/a8ff3f7c-8afe-4848-83da-ab9d05c8bbfe/0
Architectural Significance
- Core Functionality
- Complexities – – Normalizing bib and item data from three ILS systems and de-normalizing feeds for all applicable Discovery systems
Receive Collection Updates
In this use-case the ILS systems will retrieve collection updates from ReCAP middleware through SFTP drops. ReCAP middleware will de-normalize the data sets and provide updated collection information of item records pertinent to requesting institution only.
https://www.lucidchart.com/documents/view/42baec6c-d774-47f0-b463-1002f1bd7999/0
Architectural Significance
- Core Functionality
- Complexities – Identifying the collection update and provide offline export of owning library items only.
Search for Requests
In this use-case, Middleware UI users will be able to search for requests by patron id number, item id number, and delivery location.
https://www.lucidchart.com/documents/view/de81b890-9d9b-478e-97a6-be93a37f8cb8/0
Architectural Significance
- Core Functionality
- Complexities – – Middleware UI will be provided.
Initial Accession Records
In this use-case, Partners will provide data in a specified schema that is matched against the GFA barcode file. The data will be processed, mounted in the cloud, and submitted to Solr indexing and the matching algorithm.
Architectural Significance
- Core Functionality
Process EDD Request
In this use-case, the fields required to support an electronic delivery request are detailed.
https://www.lucidchart.com/documents/view/cd607093-d2d5-454e-962b-81932a90f809/0
Architectural Significance
- Core Functionality
SCSB Matching Algorithm
In this use-case, the Matching Algorithm required to identify duplicate titles is defined.
Architectural Significance
- Core Functionality
Development Environment
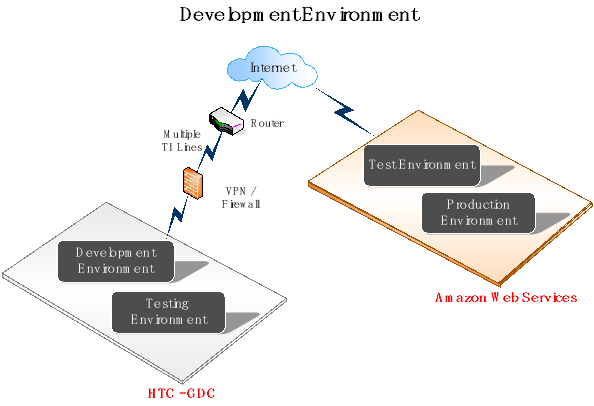
AWS Infrastructure
Following architecture diagrams depict the various environments.
Amazon Cloud Configuration (Dev Instance)
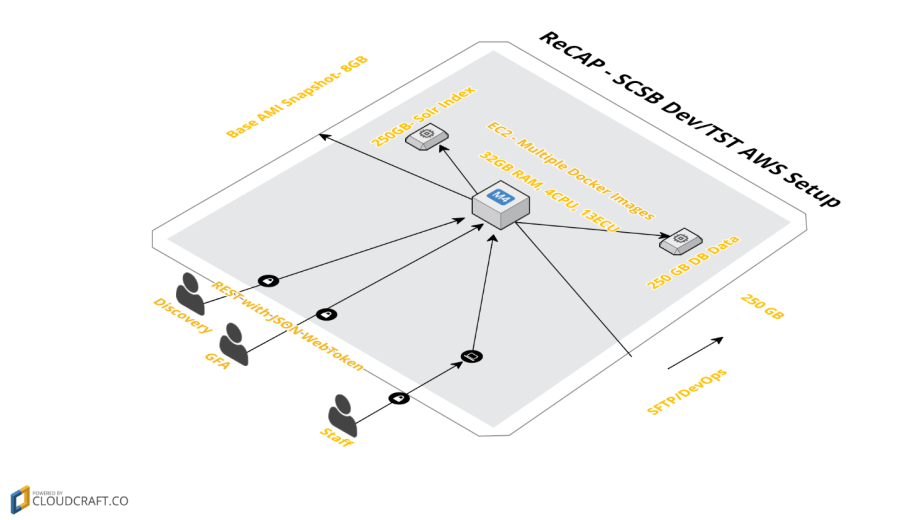
- Purpose: The development environment is primarily used for testing the local code developed in the AWS environment.
- Users : Development team
- Reliability/Lifespan This environment could be destroyed and re-created ad-hoc and hence may not have a 100% uptime guarantee.
Component | Name | Quantity |
Database | MySQL installed on EC2 | 1 |
DB Single AZ Storage (250 GB storage) | 1 | |
Web Server | EC2 - Heavy Utilization Standard Large(7.5 GiB of memory, 4 EC2 Compute Units (2 virtual cores with 2 EC2 Compute Units each), 850 GB of local instance storage, 64-bit platform) | 1 |
EBS Optimization Fee for the Extra Large Instance | 1 | |
EC2 - Heavy Utilization Standard Medium(3.75 GiB of memory, 2 EC2 Compute Units (1 virtual core with 2 EC2 Compute Units each), 410 GB of local instance storage, 32-bit or 64-bit platform) | 1 | |
Storage | EBS Storage(250 GB storage) | 1 |
Backup Storage | S3 Snapshot of EBS Volumes (500 GB storage) | 1 |
Amazon Cloud Configuration (Pre-Prod/Prod Instance)
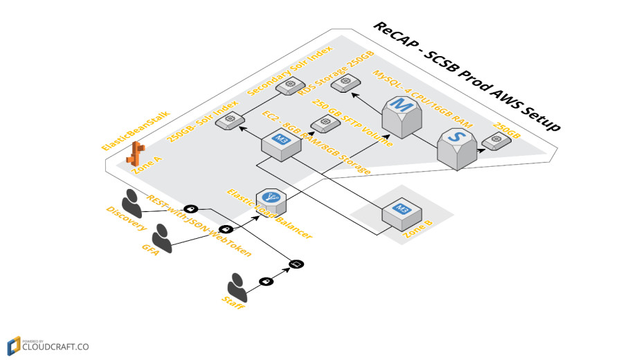
1. Purpose: The test environment is primarily used for testing the verified code from the development environment.
2. Users: Partner library systems, GFA (Inventory Management System)
3. Reliability/Lifespan This environment should be considered stable and should be available 100% of the time.
Component | Name | Quantity |
Database | RDS - Heavy Utilization Extra Large Single AZ (15 GB of memory, 8 ECUs (4 virtual cores with 2 ECUs each), 64-bit platform, High I/O Capacity, Provisioned IOPS Optimized: 1000Mbps) | 2 |
DB Single AZ Storage (250 GB storage) | 1 | |
Provisioned IOPS | 1 | |
Web Server | EC2 - Heavy Utilization High CPU Extra Large(7 GiB of memory, 20 EC2 Compute Units (8 virtual cores with 2.5 EC2 Compute Units each), 1690 GB of local instance storage, 64-bit platform) | 2 |
EBS Optimization Fee for the Extra Large Instance | 2 | |
EC2 - Heavy Utilization Standard Medium(3.75 GiB of memory, 2 EC2 Compute Units (1 virtual core with 2 EC2 Compute Units each), 410 GB of local instance storage, 32-bit or 64-bit platform) | 1 | |
Storage | EBS Storage(250 GB storage) | 1 |
Provisioned IOPS | 1 | |
Backup Storage | S3 Snapshot of EBS Volumes (500 GB storage) | 1 |
Load Balancer | Elastic Load Balancer | 1 |
Amazon Cloud Configuration (QA & Development Instance)
Component | Name | Quantity |
Database | RDS - Heavy Utilization Large Single AZ (7.5 GB memory, 4 ECUs (2 virtual cores with 2 ECUs each), 64-bit platform, High I/O Capacity, Provisioned IOPS Optimized: 500Mbps) | 1 |
DB Single AZ Storage (250 GB storage) | 1 | |
Web Server | EC2 - Heavy Utilization Standard Large(7.5 GiB of memory, 4 EC2 Compute Units (2 virtual cores with 2 EC2 Compute Units each), 850 GB of local instance storage, 64-bit platform) | 1 |
EBS Optimization Fee for the Extra Large Instance | 1 | |
EC2 - Heavy Utilization Standard Medium(3.75 GiB of memory, 2 EC2 Compute Units (1 virtual core with 2 EC2 Compute Units each), 410 GB of local instance storage, 32-bit or 64-bit platform) | 1 | |
Storage | EBS Storage(250 GB storage) | 1 |
Backup Storage | S3 Snapshot of EBS Volumes (500 GB storage) | 1 |
Note: EC2 Compute Unit (ECU) – One EC2 Compute Unit (ECU) provides the equivalent CPU capacity of a 1.0-1.2 GHz 2007 Opteron or 2007 Xeon processor.
Deployment View
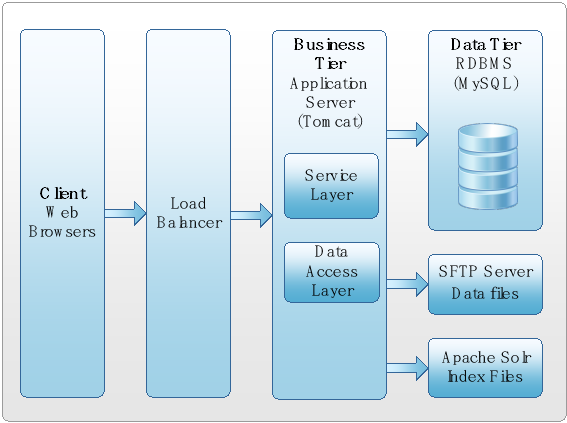
Implementation View
The implementation view shown here is only a starting point and will be refined in during development phase.
Layers
The layers, packages and its hierarchy are represented using the following diagrams. The package hierarchy starts with standard Java namespace compliant structure and then is divided into two sub-packages for the different layers viz. src – Application (Services, Data Access) and Web Content – Presentation.
Docker Container
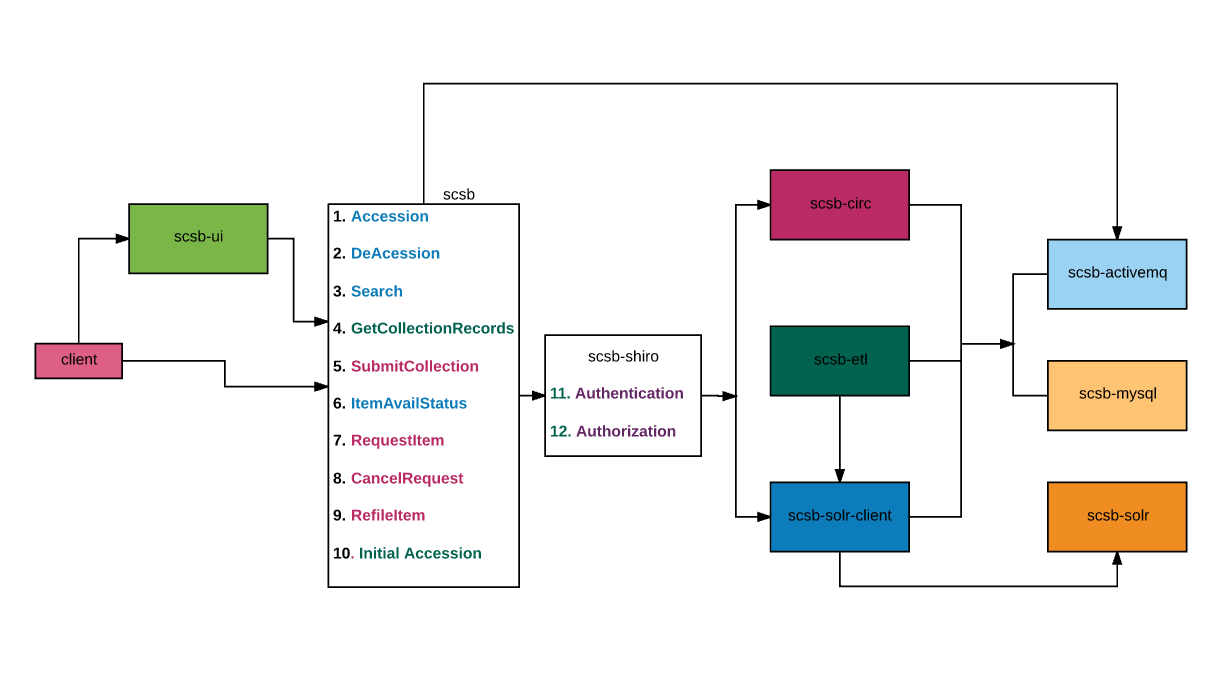
The above diagram details (source) the links between the various docker containers.
Error handling
Error handling will be implemented by leveraging the Exceptions feature of the Java language. The following guidelines are suggested when dealing with exceptions
No. | Exception Guideline | Description |
|---|---|---|
1 | Exceptions should not create additional package dependencies | Assume that a client class in package A accesses a class in package B. The class in package B should not throw an exception that belongs to package C (which is used by package B). This produces dependencies between package A and C. |
2 | Exceptions by package. | If a package's classes throw any exceptions, the package should have its own top-level checked exception. The package should then define exception subclasses for any exceptions that may be handled differently by clients. Good models for this paradigm can be found in the Java packages java.io, java.sql and javax.naming. |
3 | No blind catches of Exception | A class is responsible for knowing what exceptions it may encounter, and it must treat each exception individually. If the handling of many exceptions is identical, it could be extracted into helper methods. |
4 | No empty catch-blocks | At the very least, a catch-block should contain an assertion that it should never be reached or a comment stating that it is irrelevant |
5 | Write sensible throws clauses | Fewer (<3) the number of exceptions thrown, better it is. Always throw exceptions that make sense to the calling class, if not wrap that exception in another, which more closely captures the error type |
6 | Chaining Exceptions | Always chain exceptions so that the root cause of the error is available for logging it into the error/system log file. This is very useful for diagnosing errors in production environment |
7 | Use Message Catalogs for easy localization | Use message catalogs for message text of an exception, whose message is directly presented to the end user. This will help the application to be localized or internationalized by just adding another message catalog |
Applications when encountering an exception should always log it to the Application/System log. Lower level components should avoid writing to an error/system log.
Data View
All information pertaining to the data can be found at the Data Architecture page of the ReCAP Technical Guide.
Non-Functional Expectations
Scalability
This section explains how the architecture aims to achieve scalability.
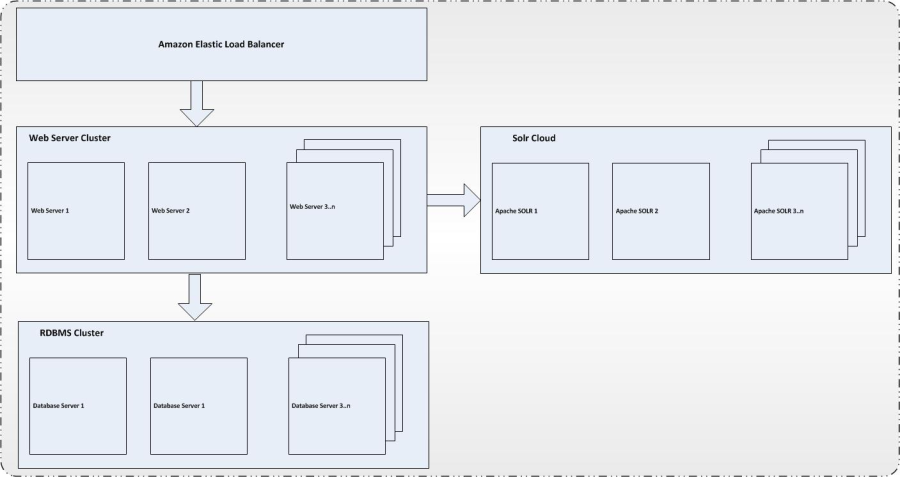
Figure 9 - Scalability
The figure above presents how the architecture aims to be scalable. There are several elements that contribute to scalability:
- Network or HTTP load balancers – These appliances or devices would perform load balancing of HTTP and other protocol specific servers. The actual mechanism of load balancing will depend upon specific device and could include mechanisms like round robin, cookie sniffing etc. In a web environment, the load balancers will balance the load between web servers. The web server maintains state (user specific). This typically means that once a session is established, a user is redirected to the same web server. Relatively inexpensive servers (nodes) could be used for the web servers. Redundant servers could be used to provide high-availability.
- Web Server Cluster – The Web server cluster appears to the client application (Browser or Service Client) as a single server. The Web server provides clustering capability. Although session state could be replicated, it could result in performance hits. The architecture presents design using sticky sessions to provide high availability and fault tolerance without compromising performance. The Web server cluster scales by adding more nodes to the cluster. The applications will need no change when the cluster scales. Again, relatively inexpensive servers could be used to enable linear scaling.
- RDBMS cluster – The RDBMS servers will be clustered to provide scalability. The RDBMS cluster appears as a single server to the user of the database. The RDBMS product takes care of data replication and clustering challenges.
- Solr Cloud – Solr Cloud creates a cluster of Solr servers representing two different shards of a collection (complete index). While shards provide distributive scaling, shard replication provides fault tolerance. Zookeeper takes care of data replication and clustering challenges.
There is no projected increase in the number of external users or anticipated growth in the number of requests on volume beyond those listed below:
| FY 2016 | FY 2017 | FY 2018 | FY 2019 | FY 2020 | |
|---|---|---|---|---|---|
| Holdings | 13,000,000 | 14,000,000 | 15,000,000 | 16,000,000 | 17,000,000 |
| Accesions | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 | 1,000,000 |
| Standard Use (2% of holdings) | 260,000 | 280,000 | 300,000 | 320,000 | 340,000 |
| Shared Use (1% of shared * ) | 163,800 | 176,400 | 189,000 | 201,600 | 214,200 |
| ↓ | ↓ | ↓ | ↓ | ||
| Daily Vol | Daily Vol | Daily Vol | Daily Vol | ||
| Bib Records (New) | 4,000 | 4,000 | 4,000 | 4,000 | |
| Projected Std Use | 1,120 | 1,200 | 1,280 | 1,360 | |
| Projected Shared Use | 706 | 756 | 806 | 857 | |
| Proj Total Requests | 1,826 | 1,956 | 2,086 | 2,217 | |
* This is calculated as 1% usage of materials newly accessible to each partner. "Newly accessible" assumes that 70% of the total ReCAP holdings are shared, and that 60% of those holdings are "new" in the partner's discovery layer. SO the formula is 1% of 60% of 80% of total holdings, times 3 partners. | |||||
Usability
Usabilty requirements are identical to the requirements existing within SCSB today.
SCSB screen changes should follow existing screen flow approach.
Usability Standards
System development activities shall conform to the following usability standards.
- The System shall be designed to be resolution independent.
- Should complaint with general naming standards.
- All Application screens should be consistent with open source branding standards.
- The system shall provide a consistent user interface, menus, and commands across all parts of the application and should follow current system usability requirements.
- Microsoft Internet Explorer 10.0
- Microsoft Internet Explorer 11.0
- Google Chrome 30.0
- Google Chrome 31.0
- Firefox 2.0.0.3
- Safari for Windows (v 5.1.7 and up)
- Safari for MAC OSX 10.9.2 (v 7.0 and up)
Availability
All systems should continue to maintain current hours of availability.
The systems must be available 95% during the hours of operation from a production implementation date to six weeks following the implementation.
- The systems must be available 98% during the hours of operation six weeks following a production implementation.
- The systems may be unavailable due to unavailability of App, Web and Database Servers.
- The systems may be unavailable due to infrastructure upgrade and maintenance activity provided such activity is scheduled in advance.
Application Availability Hours
Standard availability: Close to 24 X 7
Down Time: 0.1%(With the exception of planned outages or scheduled maintenance).
Online Availability Target : 99.9%
Fail Over: The goal of fail-over is to allow work that would normally be done by one server to be done by another server should the regular one fail. For example, Server A responds to all requests unless it has a hardware failure, or someone trips over its network cable, or the data center it is located in burns to the ground. And if Server A cannot respond to requests, then Server B can take over. Or if we simply need a service to be highly available, fail-over allows you to perform maintenance on individual servers (nodes) without taking your service off-line.
Load Balancing: Load balancing lets you spread load over multiple servers. You would want to do this if you were maxing out your CPU or disk IO or network capacity on a particular server. Alternatives to load balancing include 'scaling' vertically. e.g. getting faster or better hardware such as quicker disks, a faster CPU or a fatter network pipe.
Backup and Recovery: In general, backup and recovery refers to the various strategies and procedures involved in protecting your database against data loss and reconstructing the database after any kind of data loss.
- Physical Backups and Logical Backups
- Errors and Failures Requiring Recovery from Backup
Performance
This section presents how the architecture addresses performance related issues.
Basic performance metrics are latency and throughput. Latency is measured as the time elapsed between request and response and throughput as the number of requests handler per second. In an ideal world, the latency should not increase and throughput should scale linearly as the load increases.
Performance related issues needs to be investigated at various points of the architecture. Some common elements that should will be subjected to performance tuning are:
- Middleware – Middleware technologies like ESB or other distributed technologies are primary candidates for performance tuning as issues like network round-trips and network latency could become critical.
- Database – Database access and processes like joins and sorts are candidates for performance tuning.
- Search Engine – Solr caching is an candidate to improve search performance by leveraging cached queries and results
On-line / Services Performance Requirements
Business Function Counter | Business Function Description | Service Level Agreement | Testing Results (Date) (seconds) | Currently Meeting Business Requested SLA?( Date) |
|---|---|---|---|---|
1 | Search SCSB Collection | < 1 second | ||
2 | Request Item | ~ 1- 2 seconds | ||
3 | Validate Request | < 1 second | ||
4 | Place Hold on Item | ~1-2 seconds | ||
5 | Recall Item | ~1-2 seconds | ||
6 | Ongoing Accession Item | ~1-2 seconds | ||
7 | Deaccession Item | ~1-2 seconds | ||
8 | Re-file Item | ~1-2 seconds | ||
9 | Check Item Availability | < 1 second | ||
10 | Get Shared Collection Items | < 30 seconds for 10K Items | ||
11 | Submit Collection Information | TBD | ||
12 | Receive Collection Updates | TBD | ||
13 | Search for Requests | < 1 second | ||
23 | Initial Accession Records | ~1-2 seconds | ||
| 24 | SCSB Matching Algorithm | |||
25 | Process EDD Request | ~1-2 seconds | ||
| 26 | Non-owning bib and item req | TBD | ||
| END TO END TIME |
Modifiability
Modularization and encapsulation of components and functionality shall be used throughout the development of this software.
Testability
- All the logical layers in the application architecture should be able to be independently unit tested without any interdependencies on each other.
- Proper testing tools should be used for unit testing and the execution of unit tests should be automated.
Security
Authentication:
SCSB offers UI features that may or may not need a user to be logged in and also access to various functions via RESTful APIs. In either case, SCSB will implement exchange of credentials/tokens to authenticate a user for any secure operations.
Authorization: User Roles Management
Each of these user roles has been configured with a user role profile and an undefined scope. Because the scope is undefined for these user roles, they can exercise their user profiles on all management packs, queues, groups, tasks, views, and form templates. The following table lists the default user roles, their associated user role profiles, and scope.
User role | User role profile | Scope |
Administrators | Administrator | Global |
Advanced Operators | Advanced Operator | Global |
End Users | End User | Global |
Security Testing
Security testing is a process intended to reveal flaws in the security mechanisms of an information system that protect data and maintain functionality as intended. Due to the logical limitations of security testing, passing security testing is not an indication that no flaws exist or that the system adequately satisfies the security requirements
Design Constraints
All Impacted Applications/Components
Existing data must never be negatively impacted by new changes / implementations Application, database designs must be flexible, and extensible, supporting business performance, accessibility, scalability and availability requirements mentioned above.
Application Controls
The design for the enhancements should adhere to the mentioned controls
- Any exception occurring in the system should be recorded and reported.
- If an online function fails, system should return users to a functional application and inform user within 15 seconds that function failed.
- All services, APIs or modules will provide a return code status to determine if the execution is successful or not. If the return code fails that, a unique return code will identify the cause of the problem.
Development Must Comply with Standards
Application development must adhere with relevant existing (open, de-facto) patterns, coding standards and best practices and should include a formal validation process to assure that the enhancements are reliable, functional, and scalable and met business requirements.
This project will adhere to published SOA standards.
Modularization and Logical Partitioning
Modularization breaks large business systems and applications into smaller components and support concurrent maintenance. Logical partitioning resolves consistency problems attributable to redundant process and data. The scope of the enhancements should be designed in such way that they are componentized (to be reusable) and modularized by business function.
Use of Open Source Libraries
Architecture recommends wherever applicable for the enhancements for this project that applications should utilize the reusable assets.
Use of Framework Services
For the new services and operations, the enterprise service bus architecture batch, online and web services will be used.
Use of Mainstream/Mid-tier Technologies
Industry-proven mainstream technologies that conform to industry standards and open system architectures should be applied wherever possible.
Proposed Development Environment
Hardware
The core technology will be Java and an implementation of a servlet container. MySQL will be the relational data store and apache SOLR will be the search engine. Application development environment will be hosted in Amazon cloud on Linux. Each developer will have his or her own development setup on PC or Mac and access source code that is stored in a common source control repository such as SVN or CVS.
It is assumed that Partners (NYPL, Princeton and Columbia) will be hosting the development, QA and production environments of NCIP Responders and GFA LAS.
Software
No. | Name | Purpose |
1 | IntelliJ 16.x | Eclipse is a multi-language software development environment comprising a base workspace(Eclipse Public License (EPL)) |
2 | MySQL 5.7.14 | Open source relational database management system (RDBMS) that runs as a server providing multi-user access to a number of databases (GNU General Public License) |
3 | Tomcat 8.5.0 | Apache Tomcat is an open source web server which provides pure Java HTTP web server environment for Java code to run. (Apache License) |
4 | Apache SOLR 6.5.0 | SOLR is an open source enterprise search platform written in Java and runs as a standalone full-text search server within a servlet container.(Apache License) |
5 | Docker 1.13.1 | Containerized solution for quick deployments and application run time environment. |
6 | AWS | Deployment environment. |
7 | Jenkins 2.21 | Jenkins is a server-based system running in a servlet container providing open source continuous integration features.( Massachusetts Institute of Technology (MIT) License) |
8 | JUnit 4.12 | JUnit is a unit testing framework for the Java Programming language (Common Public License) |
9 | REST | Representational State Transfer (REST) is a software architectural style that defines a set of constraints to be used for creating web services. Web services that conform to the REST architectural style, termed RESTful web services, provide interoperability between computer systems on the Internet. RESTful web services allow the requesting systems to access and manipulate textual representations of web resources by using a uniform and predefined set of stateless operations. |
10 | Gradle 2.6 | Gradle is a build automation tool used primarily for Java projects |
11 | Java Platforms (Java 1.8 - jdk8u51) | Java is a set of several computer software products and specifications that together provide a system for developing application software and deploying it in a cross-platform computing environment (Freeware) |
| 12 | Apache ActiveMQ 5.15 | Apache ActiveMQ ™ is the most popular and powerful open source messaging and Integration Patterns server. Apache ActiveMQ is fast, supports many Cross Language Clients and Protocols, comes with easy to use Enterprise Integration Patterns and many advanced features while fully supporting JMS 1.1 and J2EE 1.4. Apache ActiveMQ is released under the Apache2.0 License |
| 13 | Spring Boot 1.4.3 | Spring Boot aims to make it easy to create Spring-powered, production-grade applications and services with minimum fuss. It takes an opinionated view of the Spring platform so that new and existing users can quickly get to the bits they need. |
| 14 | Apache Camel 2.18.0 | Apache Camel is an open source framework for message-oriented middleware with a rule-based routing and mediation engine that provides a Java object-based implementation of the Enterprise Integration Patterns using an application programming interface (or declarative Java domain-specific language) to configure routing and mediation rules. The domain-specific language means that Apache Camel can support type-safe smart completion of routing rules in an integrated development environment using regular Java code without large amounts of XML configuration files, though XML configuration inside Spring Framework is also supported |
| 15 | GIT 2.6 | Git is a version-control system for tracking changes in computer files and coordinating work on those files among multiple people. It is primarily used for source-code management in software development, but it can be used to keep track of changes in any set of files. As a distributed revision-control system, it is aimed at speed, data integrity, and support for distributed, non-linear workflows. |
| 16 | CAS 5.0.2 | The Central Authentication Service (CAS) is a single sign-on protocol for the web. Its purpose is to permit a user to access multiple applications while providing their credentials (such as userid and password) only once. It also allows web applications to authenticate users without gaining access to a user's security credentials, such as a password. The name CAS also refers to a software package that implements this protocol |
| 17 | Apache Shiro 1.4.0-RC2 | Apache Shiro is an open source software security framework that performs authentication, authorization, cryptography and session management. Shiro has been designed to be an intuitive and easy-to-use framework while still providing robust security features |
Naming and Coding Standards
Project will adopt the following industry standard naming and coding standards:
No. | Reference | URL |
| 1 | Code Conventions for the Java TM Programming Language | http://www.oracle.com/technetwork/java/javase/documentation/codeconvtoc-136057.html |
| 2 | Guidelines, Patterns, and code for end-to-end Java applications | http://www.oracle.com/technetwork/java/namingconventions-139351.html |
| 3 | J2EE Patterns | |
| 4 | Securing Web Applications | |
| 5 | CERT Secure Coding Standards – Java Guidelines | https://www.securecoding.cert.org/confluence/display/java/Java+Coding+Guidelines |
6 | Secure Coding Guidelines for Java SE | http://www.oracle.com/technetwork/java/seccodeguide-139067.html |
| 7 | Open Web Application Security Project | https://www.owasp.org/index.php/OWASP_Secure_Coding_Practices_-_Quick_Reference_Guide |
| 8 | Cloud Infrastructure | https://media.amazonwebservices.com/AWS_Cloud_Best_Practices.pdf |