Solr Indexing Guide
- SK
- Hari Krishnan (Unlicensed)
Shared Collection Service Bus (SCSB) uses Apache Solr to provide fast, enterprise grade search performance to the bibliographic search feature. The data needs to be indexed for Solr to search and retrieve the search results. When the application is installed and started for the very first time it might need to index the relevant data. Depending on the volume of data the time taken for the indexing process varies. Subsequent updates to the data are immediately indexed in real time.
SCSB allows the administrator to initiate the index process through a Graphical User Interface (GUI).
SCSB SOLR ADMIN:

The SCSB Solr Admin page has six tabs viz. Solr Full Index, Solr Partial Index , Initial Matching Algorithm , Ongoing Matching Job , Generate Reports and Request Re-Submit .Solr Full Index allows users to initiate the indexing process, this is used for initial indexing of datas.Solr Partial Indexing is used to index any changes of modification to the exitsting data.The Initial Matching Algorithm is used to run the matching algorithm for the initail set of available data.The Ongoing Matching Job allows the user to initiate jobs related to the matching process including the ongoing accessioned items.The Generate Reports tab allows the users to export various reports post different processes such as Solr Index, Accession, Deaccession and Submit Collection. The Request Re-Submit allow the user to resubmit the pending and exception requests.
SOLR FULL INDEX :
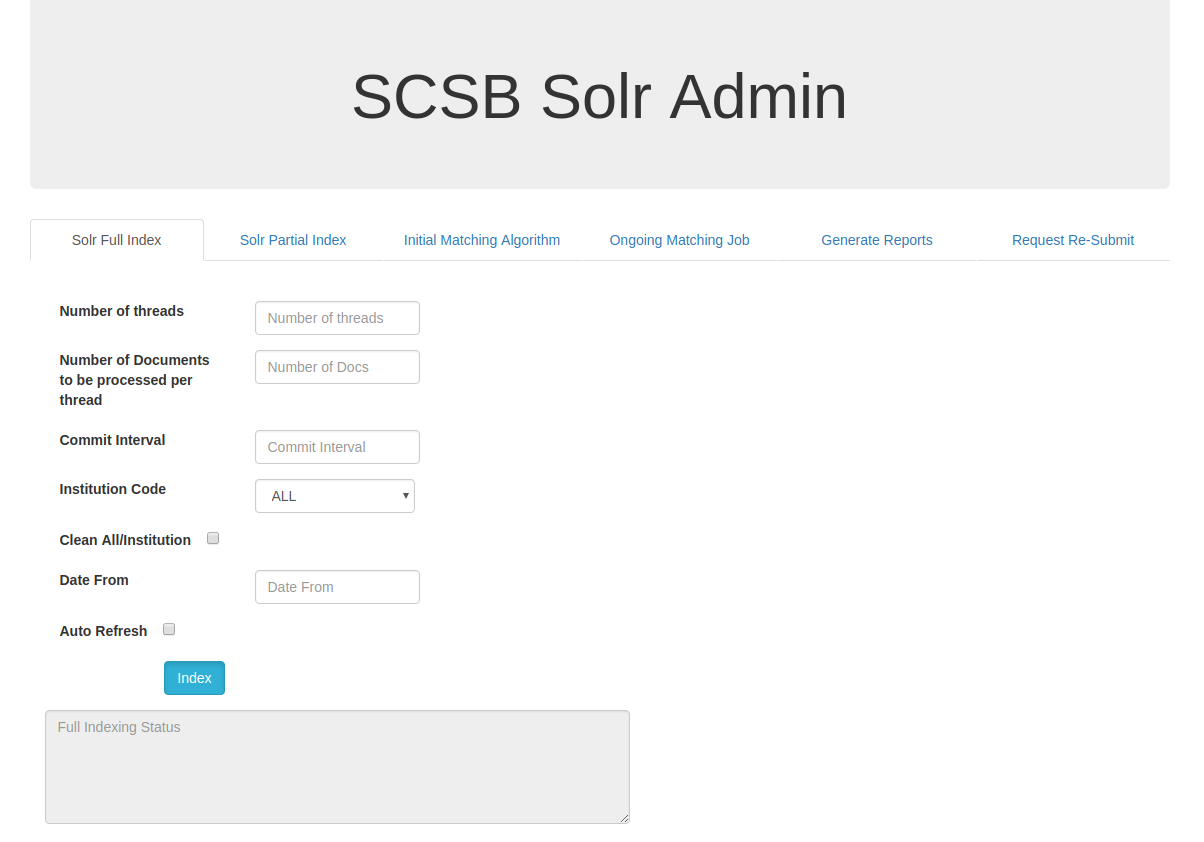
The user can define various parameters to optimize the indexing process. The Number of threads field takes in integer values and is dependent on the RAM size of the server. A 16GB RAM machine can comfortably handle 5 threads simultaneously and remains the recommended number of threads in SCSB. The Number of Documents to be processed per thread is a parameter through which the user can configure the maximum number of documents that can be processed in a thread. Past experience has suggested that 1000 is the optimal number of documents to be processed by SCSB in a single thread. Commit Interval is the number of records after which a commit is made by the Solr. 50000 remains the value in SCSB. In other words, Solr does a commit only after processing 50000 records in SCSB. Institution Code allows users to configure which institution’s records are to be indexed. Having ‘ALL’ as the value indexes all records irrespective of the institution. The Date From field is a date picker and is used to configure the date from which the records are to be processed for indexing. If the Auto Refresh checkbox is checked, the Full Indexing Status automatically displays progress in the indexing status. If the Clean checkbox is checked, any existing Solr documents from past indexing processes are removed (wiped clean) and fresh indexing commences.
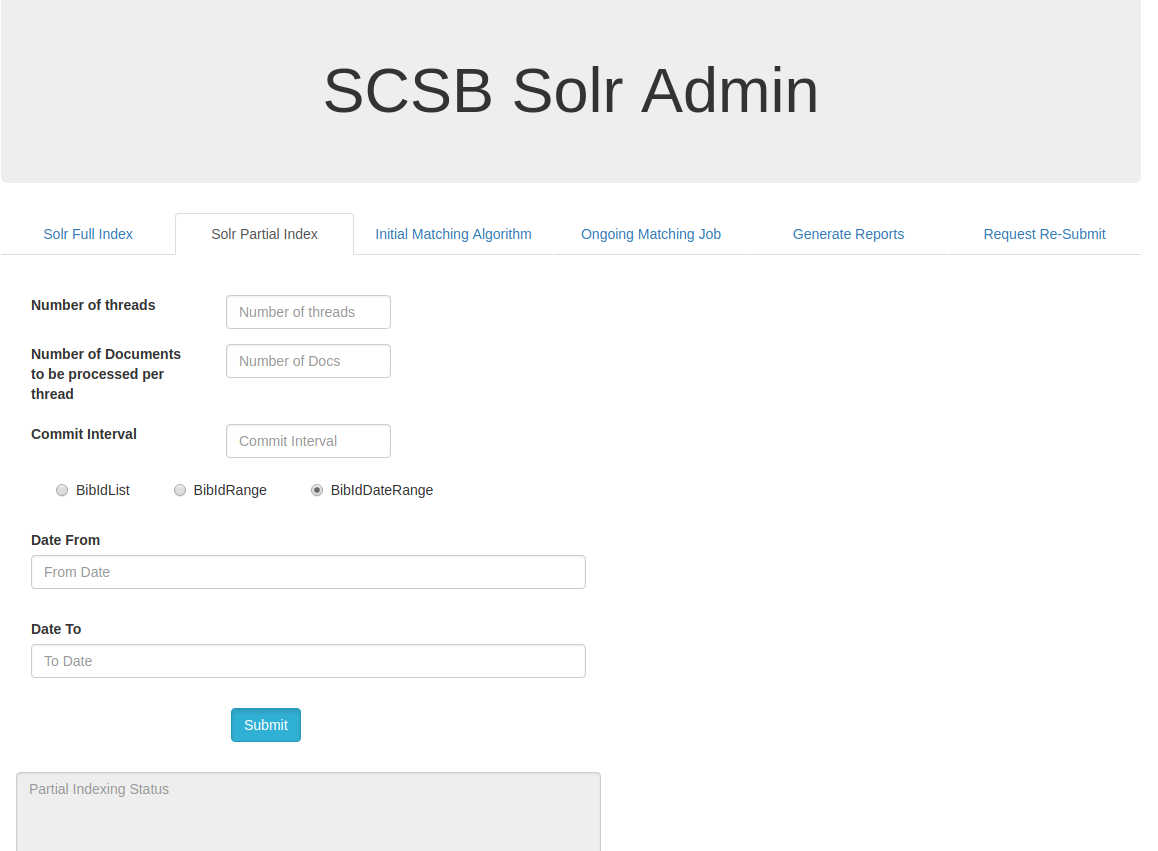
SOLR PARTIAL INDEX:
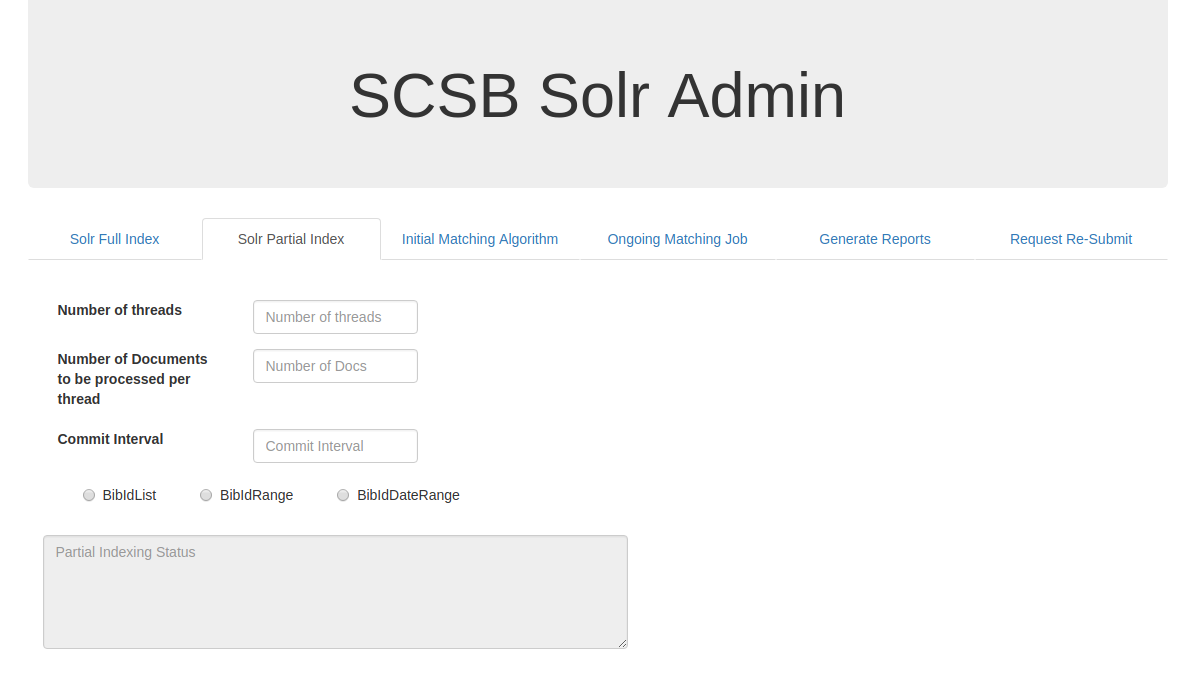
Solr Partial Index is used to index the data if any updates or modifications are required to the existing data.The Number of threads field, Number of Documents to be processed per thread , Commit interval fields are similar to the fields as mentioned for Solr Full Index.There are three available options to perform solr partial index.The options are they can be updated via BibIdList,BibIdRange and BibIdDateRange.
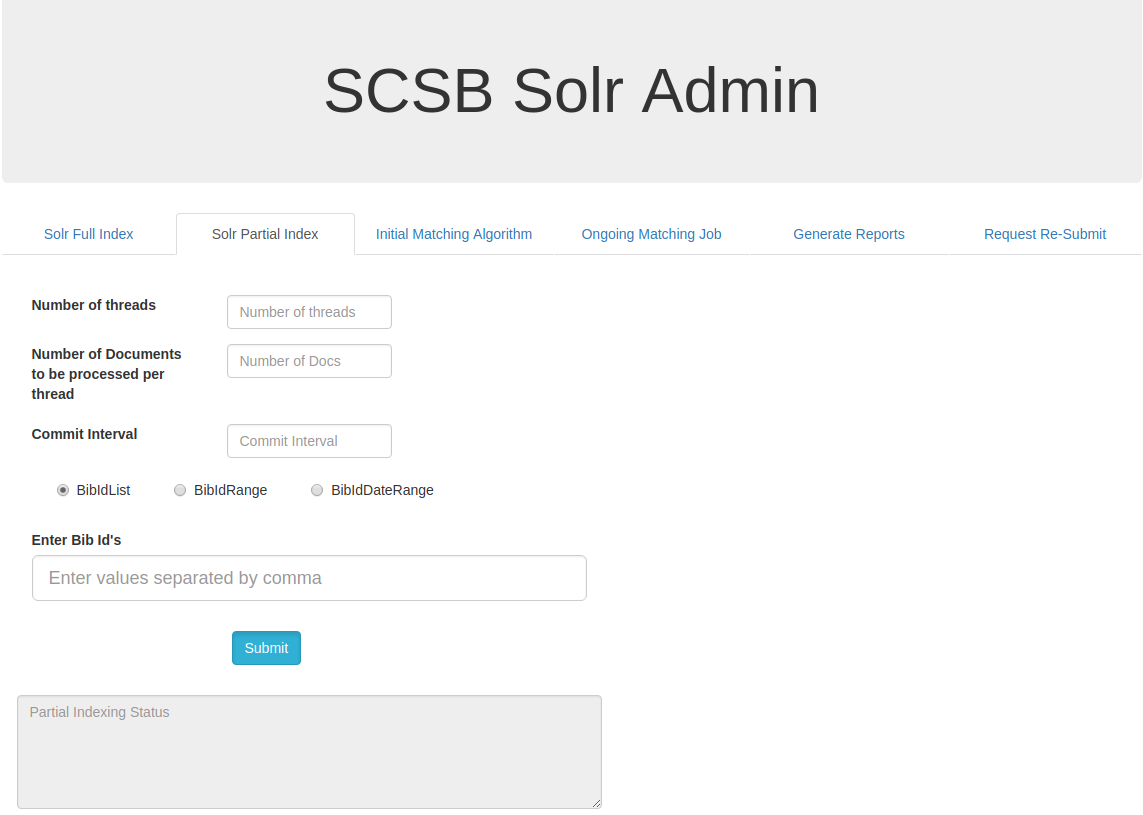
Solr Partial Index by Bib Id List :
On clicking the BibIdList , a list of SCSB Bib id's can be given with comma separated in the 'Enter Bib Id's' input box and submitted for indexing.
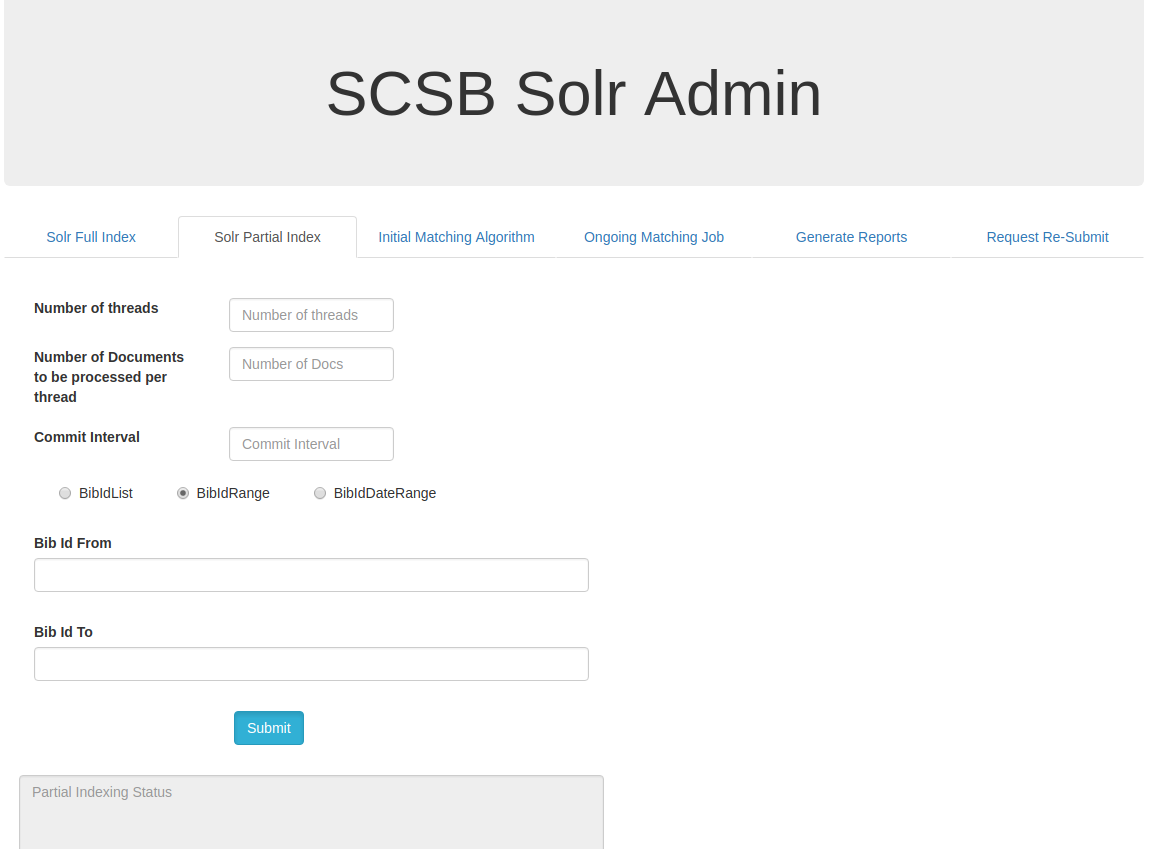
Solr Partial Index by Bib Id Range :
On Clicking the BibIdRange, a range of SCSB Bib Id's can be updated by from providing the starting range in 'Bib Id From' input box and the to range in the 'Bib Id To' input box and then on clicking the submit button the specified range are indexed.
Solr Partial Index by Bib Id Date Range :
Simillarly on clicking the BibIdDateRange, all the Bibs can be updated in the specified date range. Date from and date to can be given with the desired date range for which the updates are necessary.
Initial Matching Algorithm:
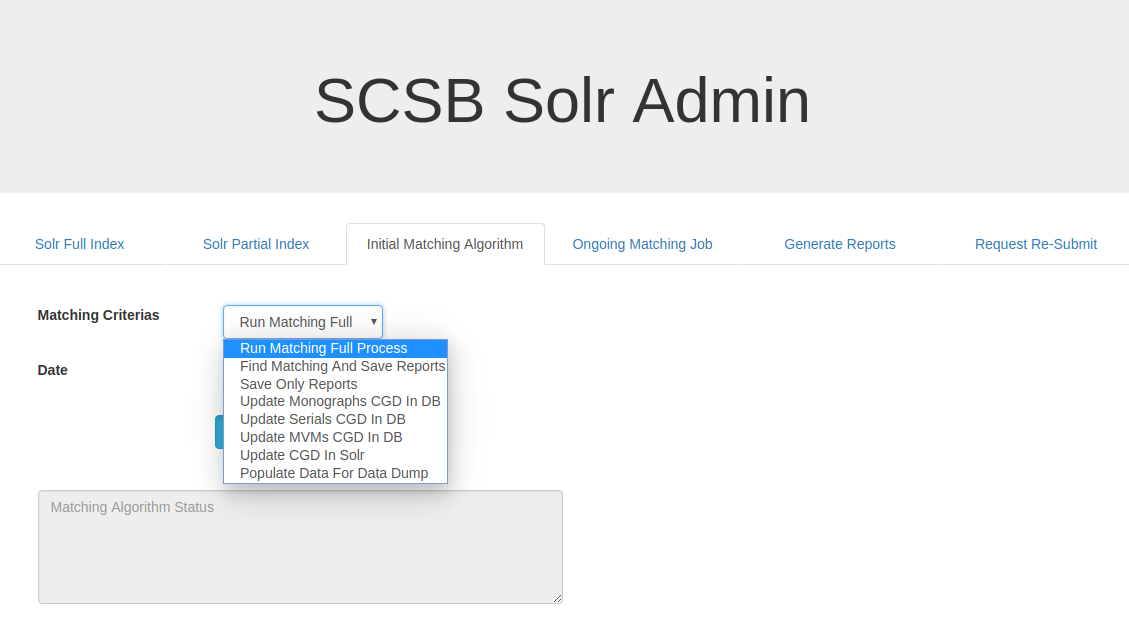
The Initial Matching Algorithm tab allows the user to individually run tasks part of the Matching Algorithm process. The Run Matching Full Process is used to run all the tasks for matching algorithm.The Find Matching and Save Reports, if selected, would process all existing records for matches depending on predefined conditions and runs a report. If Save Only Reports is selected, only the reports are generated on existing records. On selecting The Update Monographs CGD in DB/Update Serials CGD in DB/Update MVMs CGD in DB it would update CGD (Collection Group Designation) in the database if the records are found to be duplicates and depending upon their use restriction and total count of shared records of each partner. The Update CGD in Solr task if selected would update CGD in the Solr document so that the change gets reflected in the SCSB user interface. The Populate Data For Data Dump task if selected would populate duplicate record information in SCSB XML data. This information is picked up later by the data dump API while generating records.
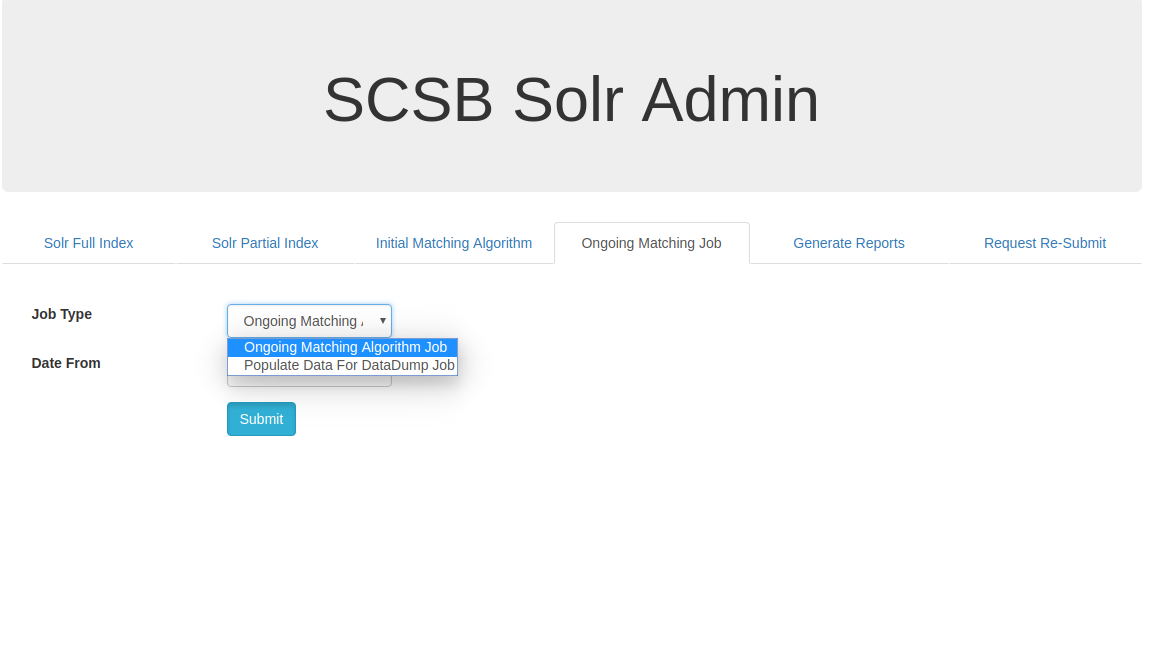
Ongoing Matching Job:
Generate Reports:
Under the Ongoing Matching Job tab, the user can initiate individual jobs part of the Ongoing Matching algorithm. Ongoing Matching algorithm runs as part of the ongoing accession process. When new bibliographic items are added to existing ReCAP collection, ongoing matching algorithm looks for duplicates and updates the CGD of the records as per predefined conditions. The Ongoing Matching Algorithm Job identifies duplicates and updates CGD while the Populate Data For DataDump Job records items that are duplicates to the SCSB XML for future export as part of data dump API.
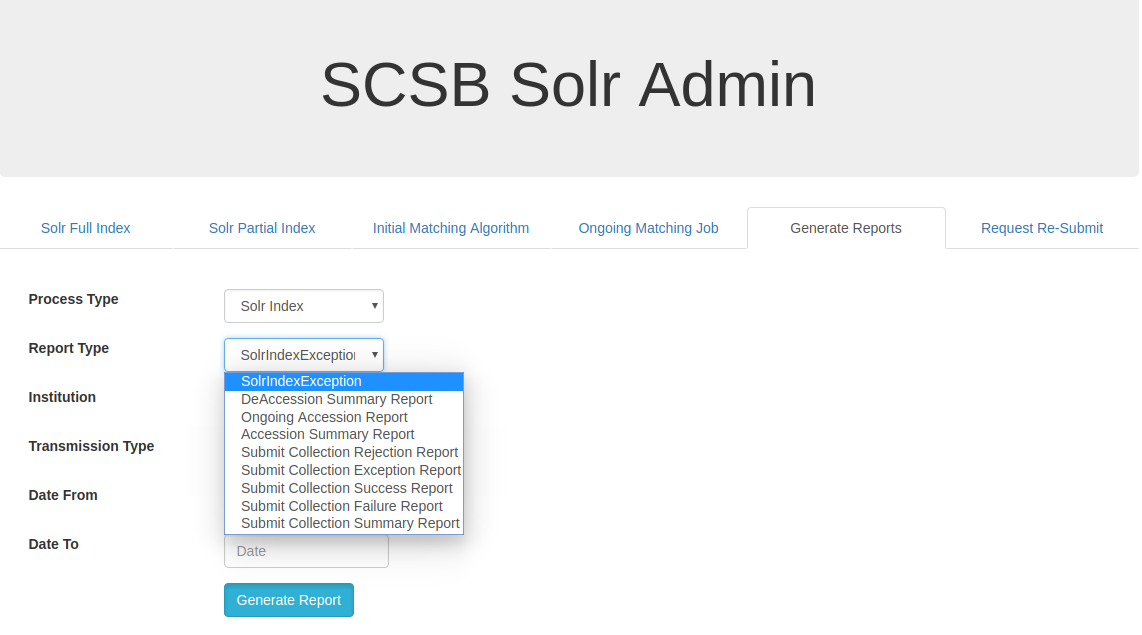
The Generate Reports tab allows the user to generate a list of reports such as the solr index exception,deaccession summary report, ongoing accession report, accession summary report, submit collection rejection report , submit collection exception report , submit collection success report,submit collection failure report and submit collection summary report .The reports can be generated for all partner institutions or for specific institutions through the Institution dropdown. Transmission of these reports are through the file system (in the server where it is hosted) or a configured FTP location, selected through the Transmission Type dropdown. The reports can be generated for the specific date range to by specifying the date range in Date From and Date To fields.
Request Re-Submit:
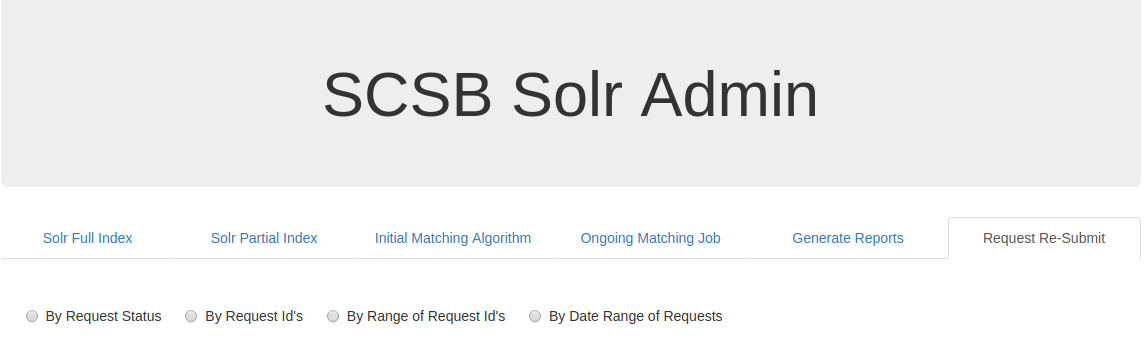
The Request Re-Submit tab can be used to resubmit the requests based on the available option such as by request status, by request id's , by range of request id's and by date range of requests.
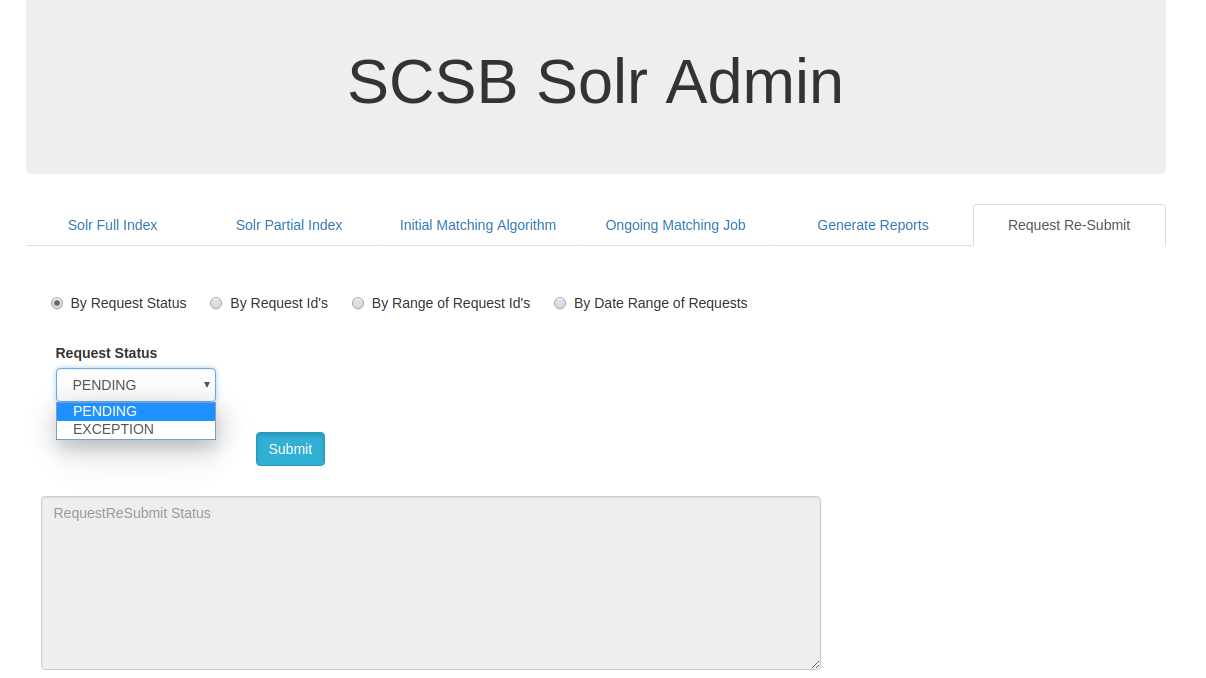
Request Resubmit by Request Status:
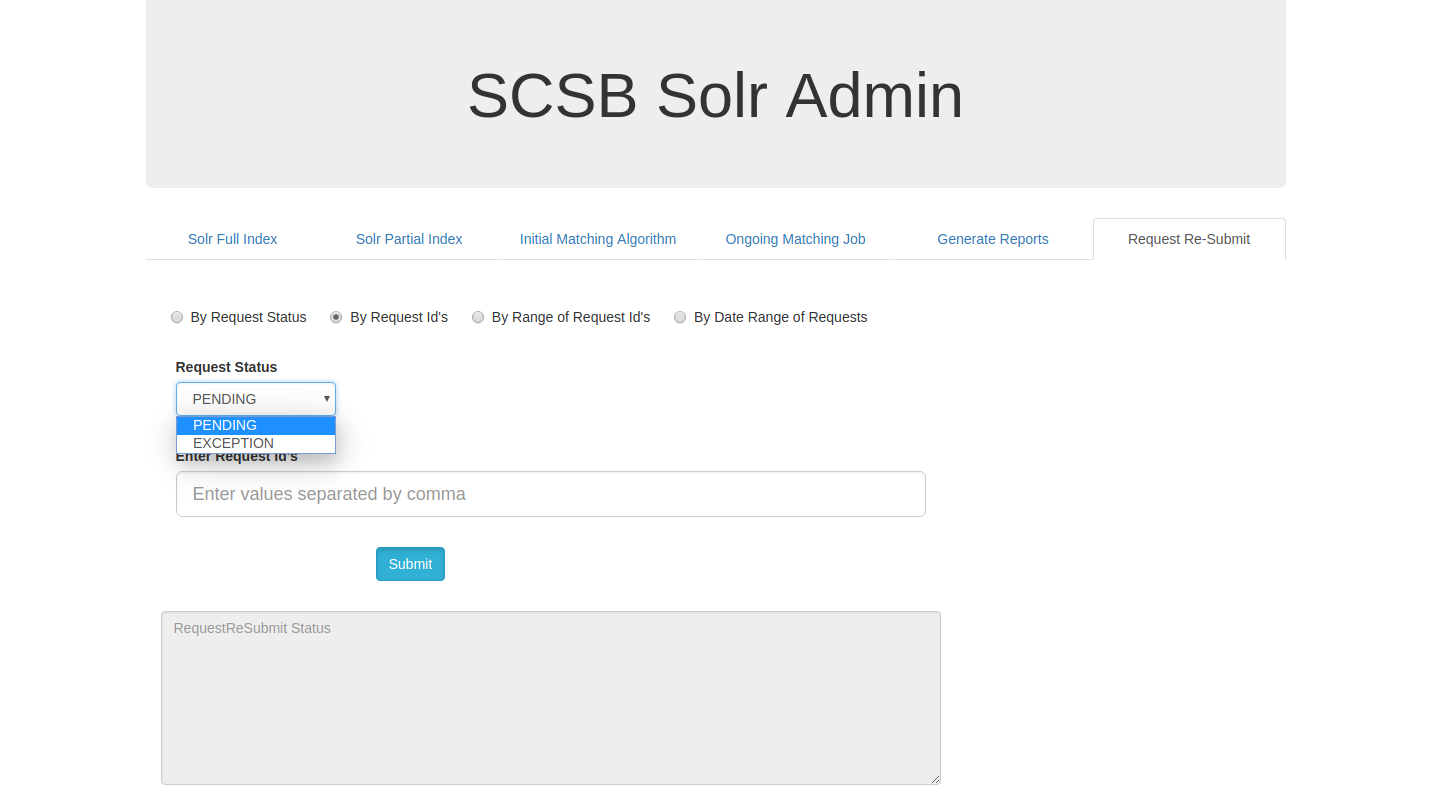
Request Resubmit by Request Id's:
On clicking the By Request Status, a drop down with pending and exception status are available.To resubmit all the pending requests pending option must to selected and submitted . To resubmit all the exception requests Exception option should be selected and submitted.
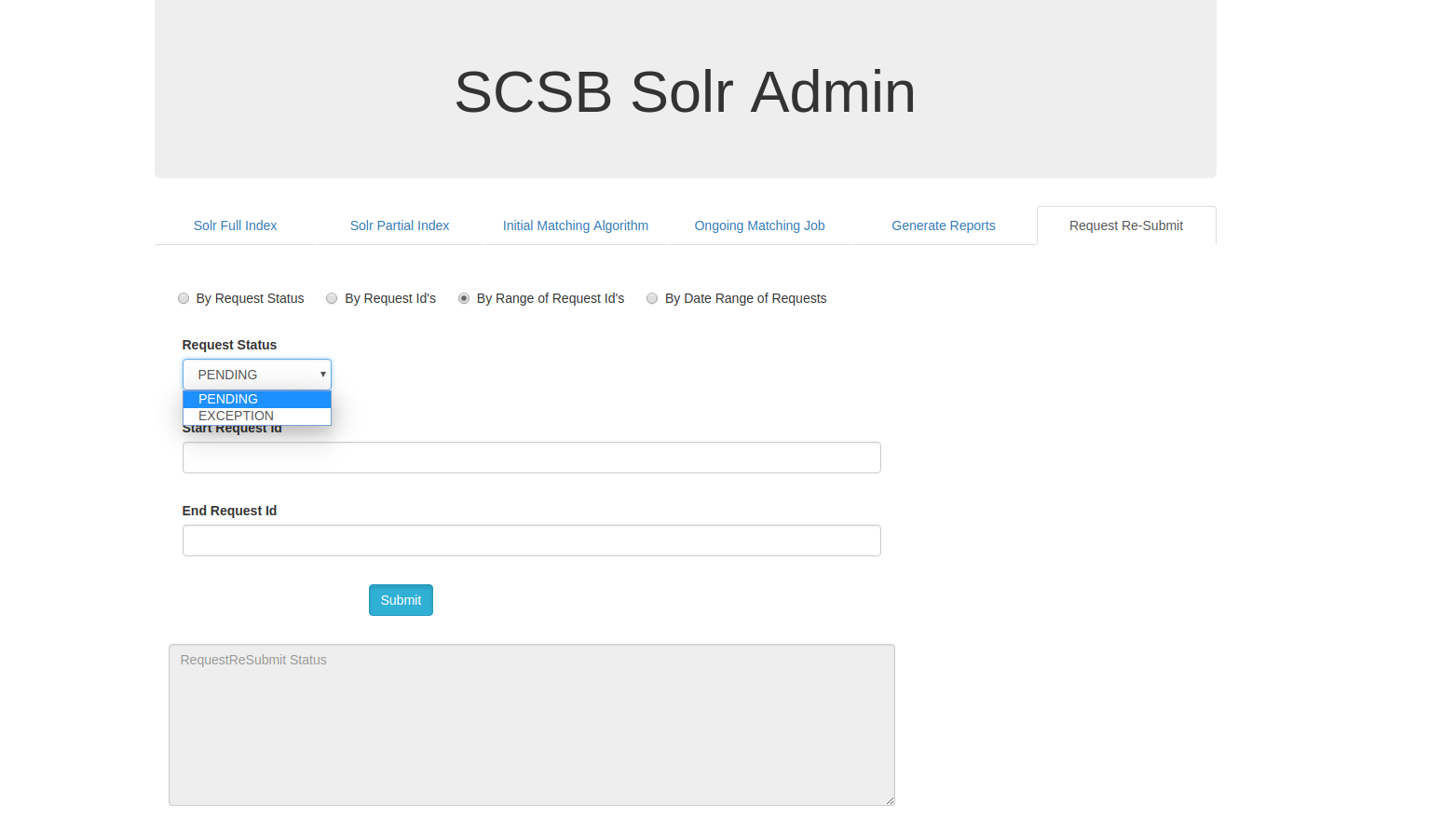
Request Resubmit by Range of Request Id's:
On Clicking the By Request Id's , requests can be resubmitted for specific user mentioned request ids for pending or exeption requests.The request id's can be given as comma separated values in the Enter Request Id's input box.
Request Resubmit by Date Range of Requests:
On clicking the By Range of Request Id's , a range of request id's can be resubmitted with request status either as pending or exception. The request id range to be resubmitted can be given in the Start Request Id and End Request Id input box.
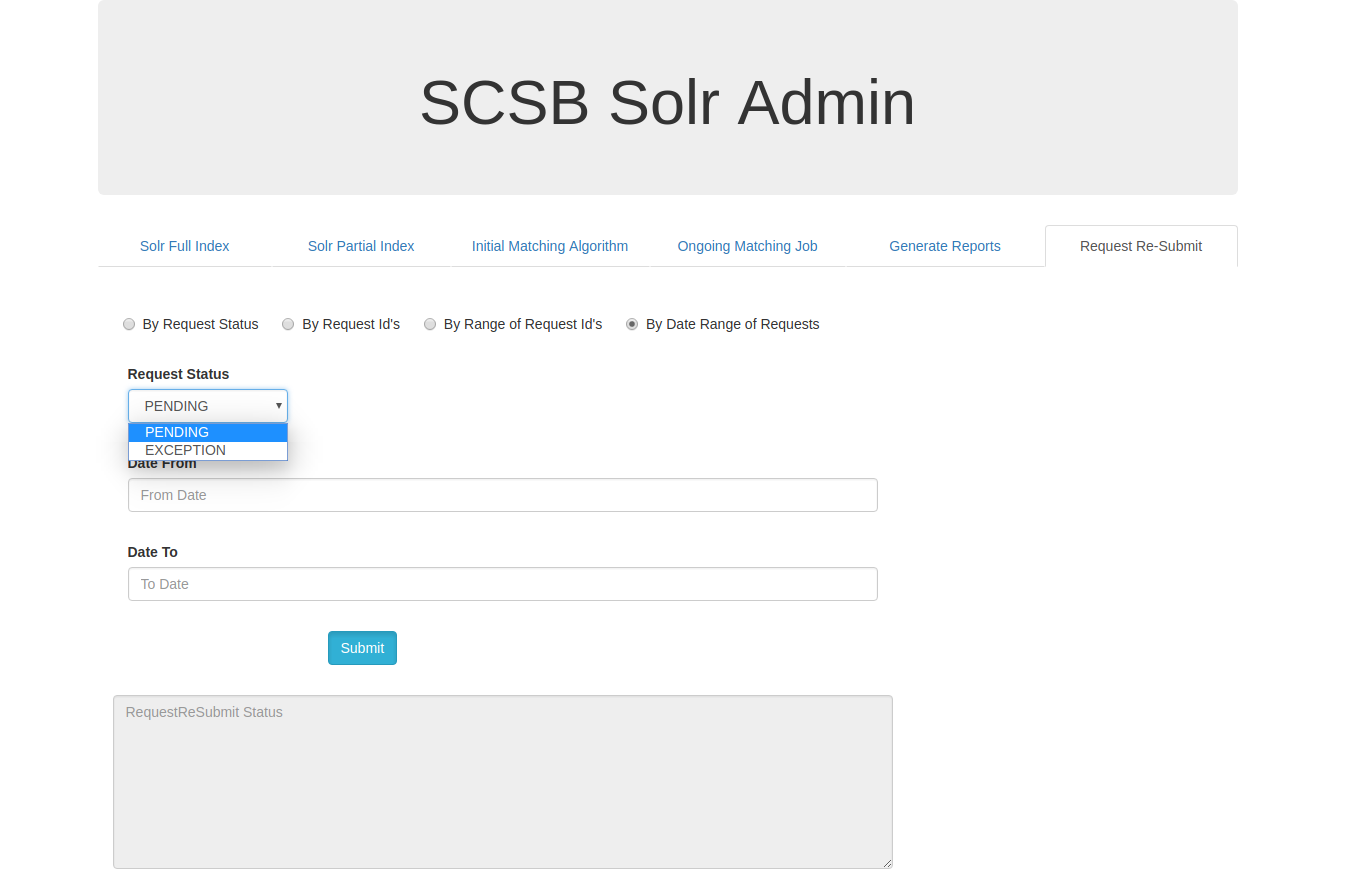
On clicking the By Date Range of Requests, request with status either as pending or exception can be updated for the specific required date range. The date range can be specified the Date From and Date To fields and submitted.